LiteResearcher: A Scalable Agentic RL Training Framework for Deep Research Agent
TL;DR
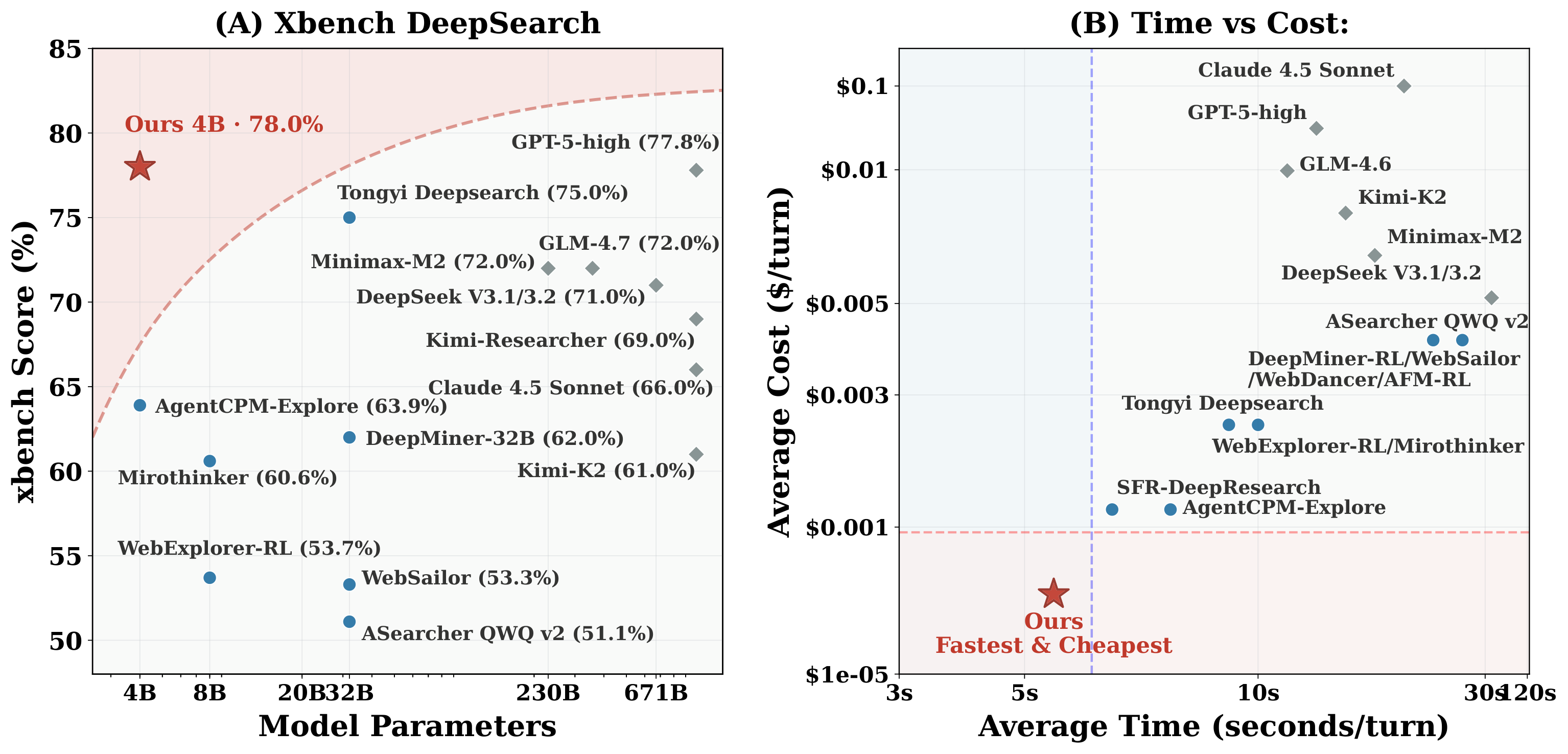
LiteResearcher-4B is a 4B deep research agent trained with zero marginal RL API cost, outperforming 30B open-source deep research agents and surpassing Claude-4.5-Sonnet and GPT-5-high on selected benchmarks. Its RL stage runs entirely in a local search/browse environment, enabling 73.2M tool calls without live search or browse API consumption.
Key Results
Abstract
Reinforcement Learning (RL) has emerged as a powerful training paradigm for LLM-based agents. However, scaling agentic RL for deep research remains constrained by two coupled challenges: hand-crafted synthetic data fail to elicit genuine real-world search capabilities, and real-world search dependency during RL training introduces instability and expensive cost, which limit the scalability of Agentic RL.
LiteResearcher is a training framework to make Agentic RL scalable and low-cost: by constructing a lite virtual world that mirrors the real-world search dynamics, we enabled a continuously improving training recipe that empowers a tiny search agent to outperform large-scale open-source and commercial models (e.g. Tongyi DeepResearch and Claude-4.5 Sonnet). The RL stage runs entirely in a local search/browse environment, removing external API consumption during RL while preserving realistic tool-use dynamics. Specifically, on most common benchmarks like GAIA and Xbench, our LiteResearcher-4B achieves the open-source state-of-the-art results of 71.3% and 78.0% respectively, proving that scalable RL training is essential for Deep Research Agents.
Method Overview
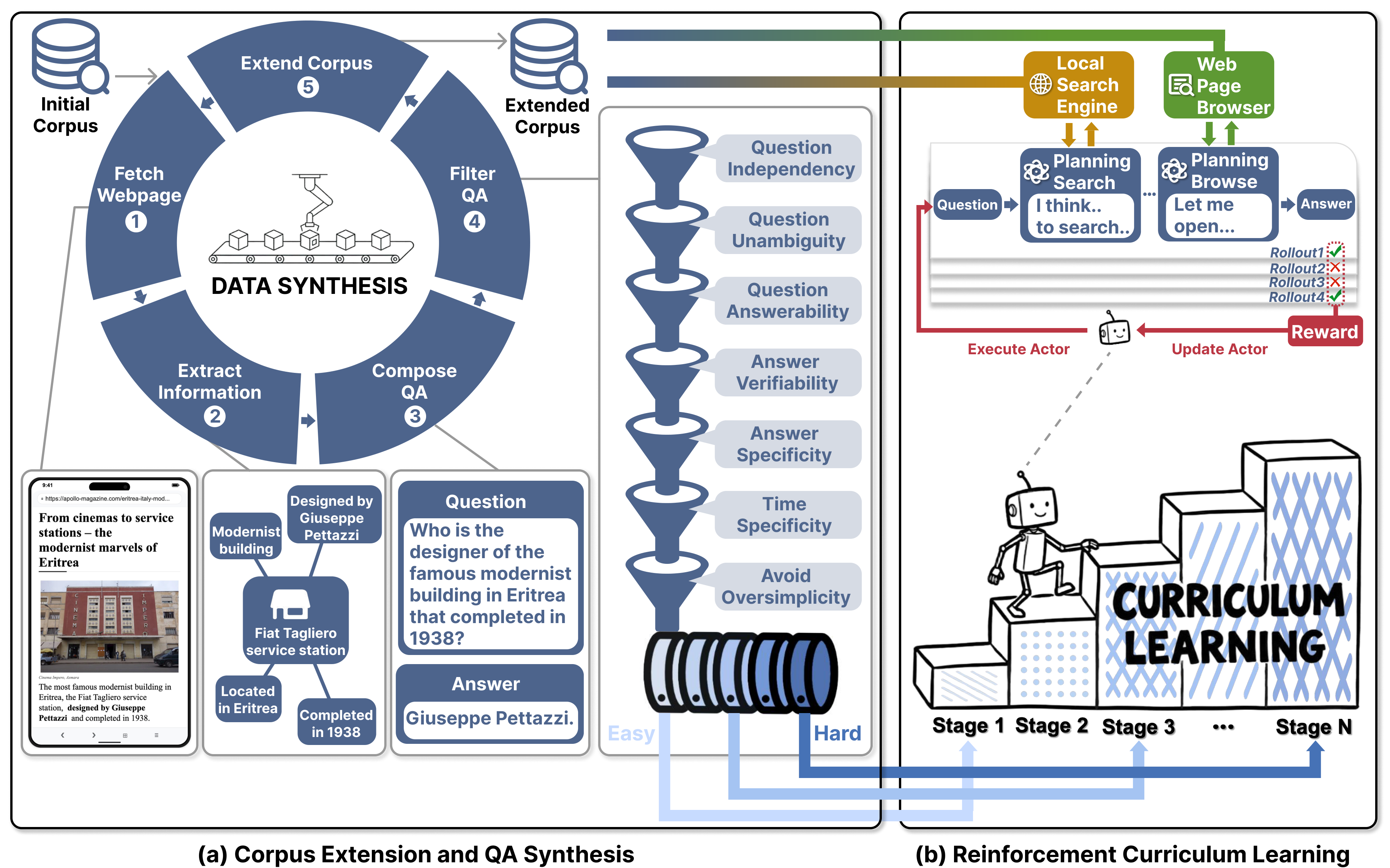
LiteResearcher constructs a virtual world with identical architecture to the real web but isolated in execution. The framework consists of three key components:
(1) Co-constructed Training Data & Corpus: We scale up information sources (32M+ webpages, 1M+ domains) and identify five atomic search capabilities — direct retrieval, aggregation, enumeration, cross-verification, and statistics — to generate diverse, realistic training tasks.
(2) Stable Local Tool Environment: A local search engine (BGE-M3 + Milvus, ~0.15s/query) and local browse tool (PostgreSQL, ~0.17s/page) that enable 73.2M tool calls during training fully locally, with no external API consumption during RL and zero marginal tool cost.
(3) Difficulty-Aware Curriculum RL: Multi-stage training that progressively increases task difficulty and context length, retaining only partially-solvable instances to maintain consistent training signal.
Main Results
LiteResearcher-4B consistently outperforms open-source models up to 8× larger and matches or exceeds proprietary systems across eight benchmarks, while remaining a low-cost 4B agent trained with fully local RL tool calls.
| Models | GAIA-Text | Browsecomp | Browse.(ZH) | HLE | Frames | Webwalker | Seal-0 | Xbench-DS |
|---|---|---|---|---|---|---|---|---|
| Commercial Models | ||||||||
| Claude-4-Sonnet | 68.3 | 12.2 | 29.1 | 20.3 | 80.7 | 61.7 | - | 64.6 |
| Claude-4.5-Sonnet | 71.2 | 19.6 | 40.8 | 24.5 | 85.0 | - | 53.4 | 66.0 |
| Deepseek-V3.2 | 63.5 | 67.6 | 65.0 | 40.8 | 80.2 | - | 38.5 | 71.0 |
| DeepSeek-V3.1 | 63.1 | 30.0 | 49.2 | 29.8 | 83.7 | 61.2 | - | 71.0 |
| Minimax-M2 | 75.7 | 44.0 | 48.5 | 31.8 | - | - | - | 72.0 |
| OpenAI-GPT-5-high | 76.4 | 54.9 | 65.0 | 35.2 | - | - | 51.4 | 77.8 |
| GLM-4.6 | 71.9 | 45.1 | 49.5 | 30.4 | - | - | - | 70.0 |
| Kimi-Researcher | - | - | - | 26.9 | 78.8 | - | 36.0 | 69.0 |
| Kimi-K2-0905 | 60.2 | 7.4 | 22.2 | 21.7 | 58.1 | - | 25.2 | 61.0 |
| Open-Source Models | ||||||||
| Mirothinker 8B | 66.4 | 31.1 | 40.2 | 21.5 | 80.6 | 60.6 | 40.4 | 60.6 |
| Tongyi Deepsearch 30B | 70.9 | 43.4 | 46.7 | 32.9 | 90.6 | 72.2 | - | 75.0 |
| ASearcher QWQ v2 32B | 58.7 | - | - | - | 74.5 | - | - | 51.1 |
| WebSailor 30B | 53.2 | - | - | - | - | - | - | 53.3 |
| WebDancer 32B (QwQ) | 51.5 | 3.8 | 18.0 | - | - | 47.9 | - | 38.3 |
| WebExplorer 8B | 50.0 | 15.7 | 32.0 | 17.3 | 75.7 | 62.7 | - | 53.7 |
| DeepMiner 32B | 58.7 | 33.5 | 40.1 | - | - | - | - | 62.0 |
| AFM-RL 32B | 55.3 | 11.1 | - | 18.0 | - | 63.0 | - | - |
| SFR-DeepResearch 20B | 66.0 | - | - | 28.7 | 82.8 | - | - | - |
| AgentCPM-Explore 4B | 63.9 | 24.1 | 29.1 | 19.1 | 82.7 | 68.1 | 40.5 | 70.0 |
| LiteResearcher-4B | 71.3 | 27.5* | 32.5* | 22.0 | 83.1 | 72.7 | 41.8 | 78.0 |
Best open-source results in bold. Results with * use a 64k context window with a memory mechanism.
Training Dynamics
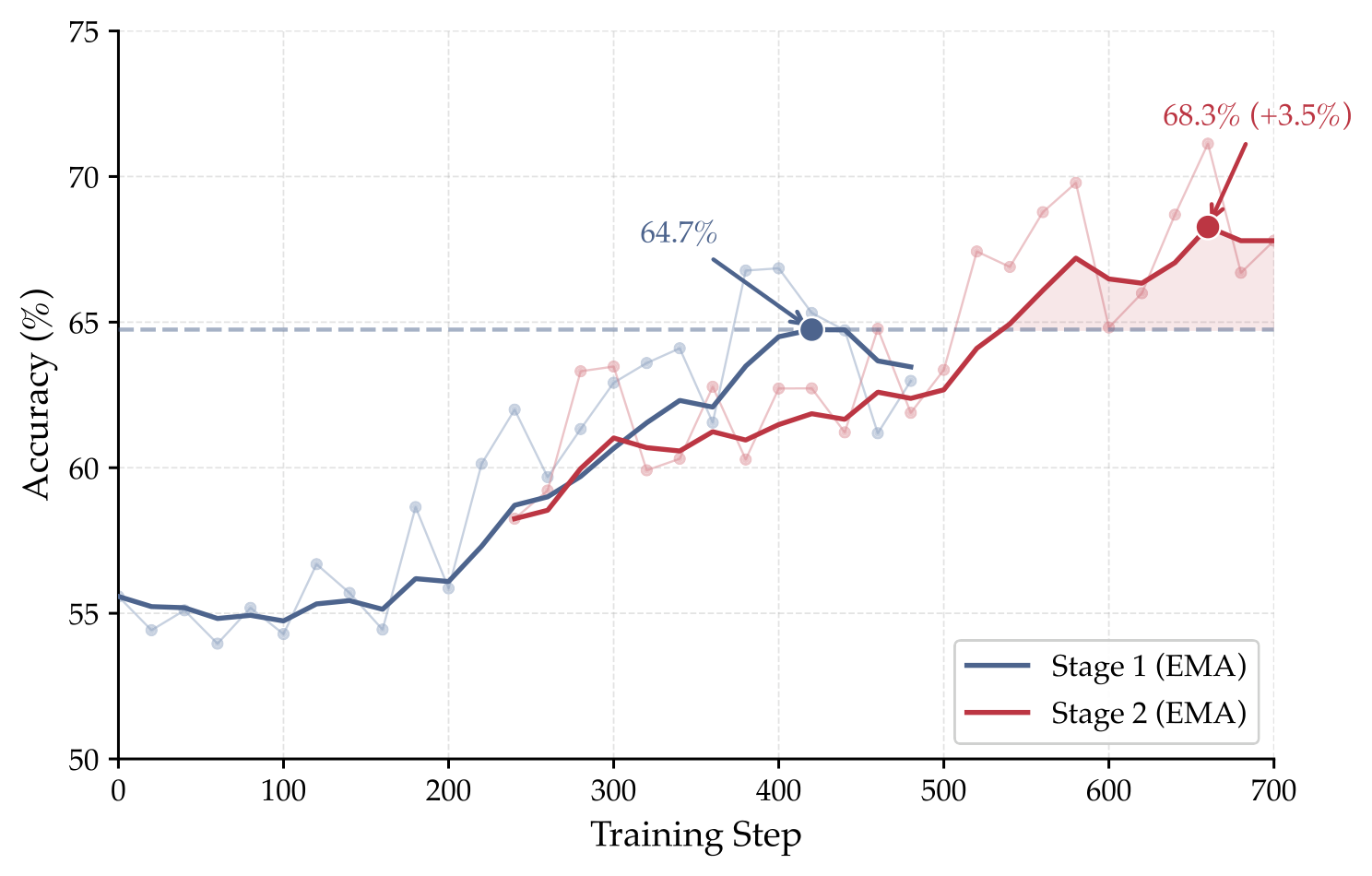
Our difficulty-aware curriculum learning prevents training saturation. Stage 2 with adjusted difficulty yields +3.6% GAIA accuracy after Stage 1 plateaus, demonstrating the importance of progressive curriculum design.
Trajectory Cases
15 hand-audited rollout trajectories from LiteResearcher-4B across 8 deep-research benchmarks. Every case is judged correct, leak-free, and verified by 4 independent Opus-4.7 (1M-context) subagents to confirm the answer is derived from cited evidence. Click any card for a quick look, or open the full step-by-step viewer.
BibTeX
@article{li2026literesearcher,
title={LiteResearcher: A Scalable Agentic RL Training Framework for Deep Research Agent},
author={Li, Wanli and Qu, Bince and Pan, Bo and Zhang, Jianyu and Liu, Zheng and Zhang, Pan and Chen, Wei and Zhang, Bo},
journal={arXiv preprint arXiv:2604.17931},
year={2026}
}